T2MLR: Transformer with Temporal Middle-Layer Recurrence
Mar 2, 2026·,,,,·
0 min read
Ziyang Cai*
Xingyu Zhu*
Yihe Dong
Yinghui He
Sanjeev Arora
 T2MLR relaxes the information bottleneck in transformer inference by passing representation from a deeper layer at the previous token position to a shallower layer of the current token position.
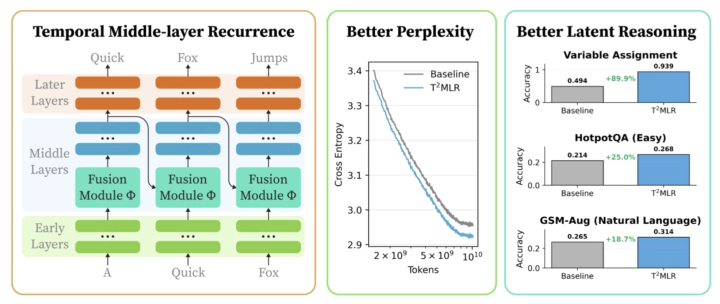
T2MLR relaxes the information bottleneck in transformer inference by passing representation from a deeper layer at the previous token position to a shallower layer of the current token position.Abstract
We introduce Transformers with Temporal Middle-Layer Recurrence (T2MLR), a generalized Transformer architecture that integrates attention and recurrence by routing a lightweight temporal pathway through the middle layers. Motivated by latent-reasoning and looped-Transformer lines of work, T2MLR injects intermediate representations from deeper layers of the previous token into earlier layers of the current token via a gated recurrent pathway, enabling iterative latent computation while preserving dense, token-level supervision. Across natural-language pretraining and multi-hop reasoning finetuning, T2MLR consistently outperforms parameter-matched Transformer baselines at the same inference compute. Moreover, we find that looping only a middle-layer block (as little as 20% of all layers) often outperforms full-layer looping. This offers a new perspective on latent reasoning in Transformers - effective iterative refinement does not necessarily require full-stack recurrence. It can instead be achieved more effectively through targeted middle-layer recurrence.
Type
Publication
LIT Workshop @ ICLR 2026